In a world where AI’s potential is often locked behind costly hardware and complex systems, Google Gemma emerges as a game-changer. This revolutionary family of lightweight, open-source language models is set to redefine how we access and deploy artificial intelligence. Developed by Google, Gemma combines cutting-edge capabilities with an impressive computational efficiency, making powerful AI more accessible than ever before.
As AI continues to shape industries across the globe, the demand for models that can run on less powerful hardware is more urgent than ever. Google Gemma meets this need head-on, offering a suite of models that deliver robust performance while keeping resource consumption low.
In this article, we’ll explore the features, applications, and potential of Google Gemma, providing insight into how this innovative model family is reshaping the AI landscape for developers, researchers, and organizations alike.
What is Google Gemma?

Google Gemma is a family of lightweight, open-source generative AI models designed primarily for developers and researchers. Created by Google DeepMind, Gemma leverages the same foundational research and technology that underpins Google’s larger Gemini models, but it is specifically optimized for efficiency and accessibility. This makes it an attractive option for those looking to implement AI solutions without the need for extensive computational resources. The models are available in various sizes and configurations, allowing users to choose the best fit for their specific applications.
The name “Gemma” is derived from the Latin word for “precious stone,” symbolizing the model’s value in the realm of artificial intelligence. This nomenclature reflects Google’s commitment to providing high-quality, valuable tools that empower developers to innovate and create responsible AI applications. The emphasis on accessibility aligns with Google’s broader mission to democratize AI technology, enabling a diverse range of users to harness its potential.
Google Gemma was officially released on February 21, 2024, introducing two initial models: Gemma 2B and Gemma 7B. The Gemma 2B model features a neural network comprising 2 billion parameters, while the Gemma 7B model includes 7 billion parameters. Both models are designed as text-to-text generative models and are available in pretrained and instruction-tuned variants, catering to different user needs. While not as large or powerful as some of Google’s flagship models—such as the Gemini Ultra, which boasts trillions of parameters—Gemma’s compact design allows it to run effectively on standard laptops and desktops, making it suitable for real-time applications that require low latency.
The Architecture of Google Gemma

The architecture of Google Gemma is primarily based on a decoder-only transformer model, which is designed to generate text outputs from given inputs. This architecture allows Gemma to excel in tasks that require text generation, such as chatbots and content creation. Unlike encoder models, which focus on understanding and processing input data, decoder models like Gemma are specifically tailored for generative tasks, making them ideal for applications that involve producing coherent and contextually relevant text.
Gemma employs several innovative techniques to enhance its performance. For instance, it utilizes multihead attention mechanisms, allowing the model to focus on various parts of the input sequence simultaneously. This capability is crucial for capturing complex relationships between tokens in the text. Additionally, the models incorporate rotary positional embeddings and knowledge distillation, which help optimize their efficiency and effectiveness in generating responses.
The architecture of Gemma also includes improvements over traditional transformer designs. For example, Gemma 2 introduces local sliding window attention and grouped-query attention, which enhance the model’s ability to manage context and improve processing speed. These advancements contribute to a more efficient use of computational resources while maintaining high-quality output.
The 7 Model Variants of Google Gemma
The Gemma family consists of several models tailored for different applications, each with unique configurations:
- Gemma: The original model introduced in February 2024, featuring two variants—Gemma 2B (2 billion parameters) and Gemma 7B (7 billion parameters). These models serve as the foundation for the entire Gemma family.
- Gemma 2: Released in June 2024, this second-generation model offers improved performance and efficiency over its predecessor. It comes in sizes of 2B, 9B, and 27B parameters, catering to a variety of computational needs.
- CodeGemma: A specialized variant designed for coding tasks, providing enhanced capabilities for code generation and completion.
- DataGemma: Focused on data-related applications, although specific details about its functionalities are less emphasized compared to other variants.
- PaliGemma: This model integrates vision-language capabilities, enabling it to handle tasks such as image captioning and visual question answering.
- RecurrentGemma: Utilizing a hybrid architecture that combines gated linear recurrences with local sliding window attention, RecurrentGemma is optimized for memory efficiency and is particularly suited for research experimentation.
Each model variant within the Gemma family offers pretrained and instruction-tuned options, allowing developers to select the most appropriate configuration based on their specific use cases. This flexibility ensures that users can leverage the strengths of each model while optimizing performance for diverse applications in natural language processing and beyond.
The Training and Performance of Google Gemma

Datasets Used for Training
Google Gemma models were trained on a diverse dataset comprising approximately 6 trillion tokens sourced from various domains. This extensive training corpus includes:
- Web Documents: A rich collection of English-language web text, ensuring the model is exposed to a broad array of linguistic styles, topics, and vocabulary. This diversity is crucial for developing a model capable of generating coherent and contextually relevant responses across different subjects.
- Code: By incorporating programming languages into the training data, Gemma enhances its ability to understand syntax and patterns, significantly improving its performance in code generation and comprehension tasks.
- Mathematics: Training on mathematical texts allows the model to learn logical reasoning and symbolic representation, equipping it to tackle mathematical queries effectively.
The combination of these varied data sources is essential for creating a robust language model that can handle a wide range of tasks and text formats while maintaining high accuracy and relevance.
Performance Benchmarks Compared to Larger Models
When evaluated against larger models such as Google’s Gemini and OpenAI’s ChatGPT-4, Google Gemma demonstrates competitive performance within its parameter size category. While not as powerful as its larger counterparts, Gemma excels in specific applications thanks to its lightweight design and efficient architecture. Performance benchmarks indicate that Gemma models can achieve high accuracy in tasks like text generation, summarization, and question answering, making them suitable for real-time applications where computational resources may be limited.
Additionally, the instruction-tuned variants of Gemma have shown significant improvements in following user instructions and generating contextually appropriate responses. This fine-tuning process involves supervised learning techniques and reinforcement learning from human feedback (RLHF), further enhancing the model’s ability to produce relevant outputs.
Innovations in Attention Mechanisms
Gemma incorporates several innovative attention mechanisms that contribute to its performance:
- Local Sliding Window Attention: This mechanism allows the model to focus on fixed-size segments of input sequences, enabling it to process information more efficiently by concentrating on relevant portions of text without being overwhelmed by the entire input.
- Grouped-Query Attention: This technique divides queries into smaller groups, allowing the model to compute attention within each group separately. This divide-and-conquer approach enhances processing speed and improves the model’s ability to manage complex input sequences.
These innovations not only optimize the model’s performance but also ensure that it operates efficiently within the constraints of smaller hardware setups. By leveraging these advanced attention mechanisms, Google Gemma positions itself as a leading choice for developers seeking powerful yet accessible AI solutions.
The Many Applications of Google Gemma

Google Gemma’s versatility enables it to excel across various fields, making it a powerful tool for developers and researchers looking to leverage AI technology in practical applications. Below are some key use cases where Gemma demonstrates its capabilities:
Natural Language Processing (NLP)
Gemma is particularly well-suited for a wide range of NLP tasks. Its ability to understand and generate human-like text allows it to be utilized in applications such as:
- Text Generation: Gemma can create high-quality written content for diverse purposes, including articles, marketing materials, and creative writing. This capability is invaluable for marketers, writers, and content creators seeking to automate their content generation processes.
- Question Answering: With its advanced language comprehension, Gemma can effectively power question-answering systems. This makes it an ideal choice for educational platforms, customer support systems, and virtual assistants that require accurate and relevant responses.
- Content Summarization: Gemma can efficiently summarize large volumes of text, extracting key information and presenting it concisely. This feature is particularly useful for researchers and professionals who need to digest extensive documents quickly.
Coding Assistance
The CodeGemma variant is specifically designed to assist developers in coding tasks. It can generate code snippets based on natural language prompts, making it easier for programmers to write code efficiently. This functionality is beneficial for educational platforms, coding assistance tools, and software development projects, helping users overcome coding challenges and improve productivity.
Data Analysis
DataGemma focuses on data-related applications, providing capabilities that enhance data analysis processes. It can be integrated with data processing frameworks like Google Dataflow to analyze customer reviews or other textual data in real time. By leveraging sentiment analysis, businesses can gain insights into customer feedback and make informed decisions based on the generated recommendations.
Vision-Language Tasks
PaliGemma extends the capabilities of the Gemma family into the realm of vision-language tasks. This model can handle applications such as image captioning and visual question answering, allowing users to interact with both textual and visual data seamlessly. This integration is particularly valuable in fields like e-commerce and education, where visual content plays a crucial role.
Real-World Applications
The real-world applications of Google Gemma are extensive and varied:
- Chatbots and Virtual Assistants: Gemma can power chatbots that engage users in natural conversations. Its ability to understand context allows for more meaningful interactions, enhancing user experience in customer service settings.
- Language Translation: By fine-tuning the models for translation tasks, Gemma facilitates seamless communication across different languages. This capability is essential for businesses operating in global markets, enabling effective multilingual customer support.
- Personalized Content Recommendations: By analyzing user preferences and behavior, Gemma can generate personalized content recommendations for platforms such as e-commerce websites or streaming services. This enhances user engagement by delivering tailored experiences.
Through these diverse applications, Google Gemma showcases its potential to transform various industries by improving efficiency, productivity, and user experience while making advanced AI technology accessible to a wider audience.
The Accessibility of Google Gemma

Platforms for Deployment
Google Gemma models are designed for flexibility and ease of deployment across various platforms:
- Google Cloud’s Vertex AI: This machine learning platform allows developers to customize and build applications using Gemma models with minimal operational overhead, making it ideal for both prototyping and production environments.
- Google Kubernetes Engine (GKE): Developers can deploy Gemma models directly on GKE, enabling the creation of scalable applications that can handle demanding workloads.
- Local Machines: Gemma models can also run efficiently on laptops and workstations, ensuring accessibility for individual developers and researchers without relying solely on cloud resources.
Integration with Popular Frameworks
Gemma is compatible with several widely-used machine learning frameworks, enhancing its usability:
- Hugging Face Transformers: This library simplifies the integration of Gemma models into various applications, providing pre-built functionalities for model inference and fine-tuning.
- PyTorch: As a leading deep learning framework, PyTorch supports the implementation of Gemma models, allowing developers to leverage its dynamic computation graph for flexible model training.
The compatibility with these frameworks ensures that developers can easily incorporate Gemma into their existing workflows.
Open-Source Nature and Community Contributions
Google Gemma is open-source, with model weights freely available for use, modification, and distribution. This commitment fosters innovation within the AI community, encouraging collaboration and experimentation. Google also supports community contributions by providing documentation and resources to help users get started with Gemma models.
Harnessing the Power of Google Gemma
Google Gemma marks a significant advancement in the realm of lightweight language models, balancing robust capabilities with efficient performance. Its design makes advanced AI accessible to a broader range of users, from developers and researchers to businesses looking to integrate AI into their operations. With its open-source nature and compatibility with popular machine learning frameworks, Gemma empowers users to build and deploy tailored solutions that meet their specific needs.
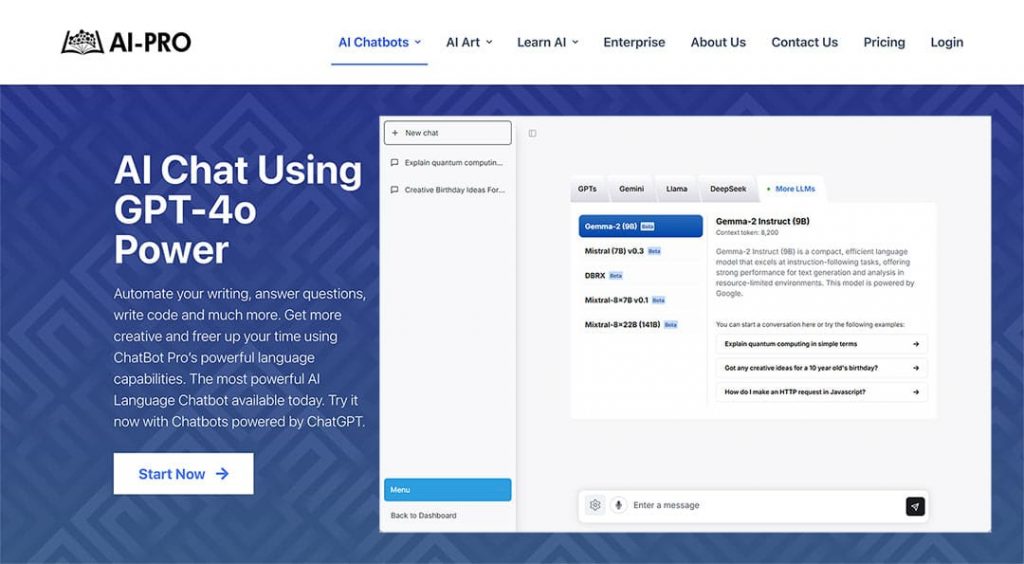
The integration of Google Gemma into applications such as AI-Pro’s ChatBot Pro highlights its significant practical impact. Through the AI-Pro ChatBot Pro Max Plan, users experience how the Gemma-2 Instruct (9B) model facilitates natural and engaging interactions while effectively managing a wide range of text generation tasks. This versatility underscores Gemma’s capability to excel in various use cases, from conversational interfaces to complex natural language processing applications, making it a powerful tool for businesses seeking innovative AI-driven solutions.
As AI continues to evolve, Google Gemma’s role in shaping the future of accessible, efficient, and responsible AI applications becomes increasingly clear. Its ability to run across different platforms, including both cloud environments and local machines, ensures that users can leverage its power without the need for excessive computational resources. Google Gemma is poised to play a key role in driving AI innovation, making it a valuable asset for organizations looking to harness the potential of AI.